如何为AI工作负载在裸机GPU和虚拟GPU之间进行选择
为您的AI项目选择合适的GPU类型可以在成本和业务成果方面产生巨大差异。第一个考虑因素通常是你需要裸机还是虚拟GPU。使用裸机GPU,您可以获得一个安装了整个GPU芯片(或多个芯片)的物理服务器,该芯片完全专用于您在服务器上运行的工作负载,而虚拟GPU意味着您可以与其他虚拟机共享GPU资源。
继续阅读,了解裸机GPU和虚拟GPU之间的关键区别,包括性能和可扩展性,以帮助您做出明智的决定。
裸机和虚拟GPU之间的区别
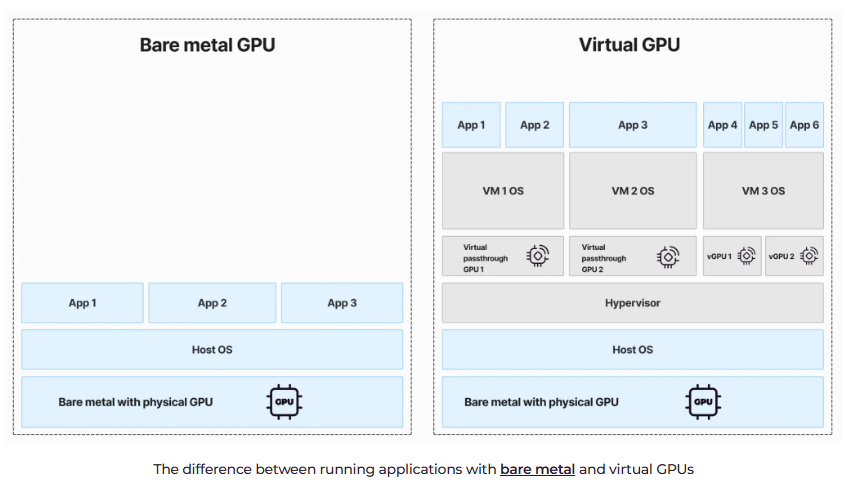
裸机GPU和虚拟GPU之间的主要区别在于它们如何使用物理GPU资源。使用裸机GPU,您可以获得一个安装了整个GPU芯片(或多个芯片)的物理服务器,该芯片完全专用于您在服务器上运行的工作负载。操作系统(OS)和硬件之间没有管理程序层,因此应用程序直接使用GPU资源。
使用虚拟GPU,您将获得一个虚拟机(VM),并根据您或云提供商的能力使用两种类型的GPU虚拟化之一:
•VM使用的整个专用GPU,也称为直通GPU
•多个虚拟机使用的共享GPU,也称为vGPU
虽然直通GPU VM可以获得整个GPU,但应用程序可以通过客户操作系统和管理程序的层访问它。此外,与裸机GPU实例不同,应用程序使用的其他关键VM资源,如RAM、存储和网络,也是虚拟化的。
使用裸机和虚拟GPU运行应用程序之间的区别
这些架构特征影响以下关键方面:
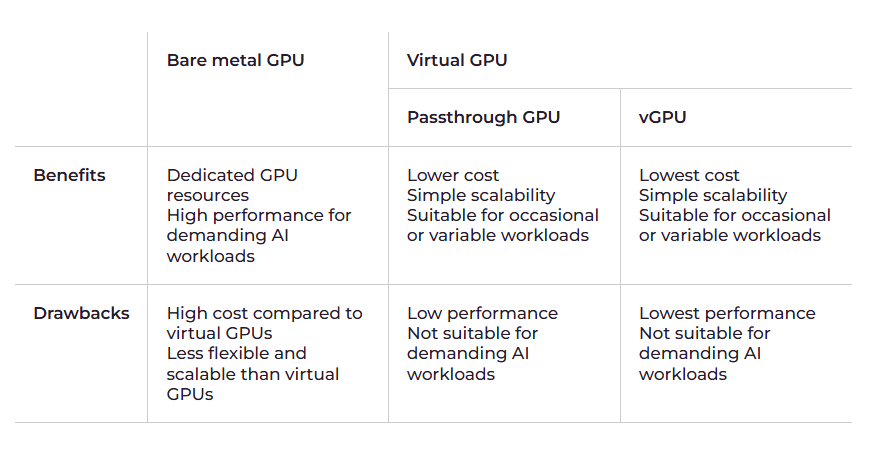
•性能和延迟:在具有虚拟GPU的VM上运行的应用程序,特别是vGPU,在相同的GPU特性下,其处理能力和延迟将低于在具有物理GPU的裸机上运行的那些应用程序。
•成本:由于上述原因,裸机GPU比虚拟GPU更贵。
•可扩展性:虚拟GPU比裸机GPU更容易扩展,因为扩展裸机GPU需要新的物理服务器。相比之下,可以在几分钟甚至几秒钟内在云中配置新的GPU实例。
•控制GPU硬件:这对于某些配置和优化至关重要。例如,当训练具有十亿个参数的大规模深度学习模型时,完全控制意味着优化性能优化的能力,这可能会对大规模数据集的训练效率产生重大影响。
•资源利用率:如果正在执行的任务不需要GPU的全部功率,GPU虚拟化可能会导致利用率不足,从而导致资源浪费。
下表总结了每种方法的优缺点:
你应该使用裸机还是虚拟GPU?
裸机GPU和虚拟GPU通常用于不同类型的工作负载。你的选择将取决于你想要执行的人工智能任务。
裸机GPU更适合需要最高性能和速度的计算密集型AI工作负载,例如训练大型语言模型。对于必须全天候不间断运行的工作负载,它们也是一个不错的选择,例如一些生产AI推理服务。最后,裸机GPU更适合用于实时人工智能任务,如机器人手术或高频交易分析。
虚拟GPU是AI/ML早期阶段和AI模型迭代的更合适选择,在这些阶段,灵活性和成本效益比最高性能更重要。具有可变或不可预测资源需求的工作负载也可以在这种类型的GPU上运行,例如训练和微调小型模型或对延迟和性能不敏感的AI推理任务。虚拟GPU也非常适合不需要专用硬件的偶尔、短期和协作的AI/ML项目,例如,包括多个机构的学术合作。
要选择正确的GPU类型,请考虑以下三个因素:
•性能要求。原始GPU速度对您的AI工作负载是否至关重要?如果是这样,裸金属GPU是一个更好的选择。
•可扩展性和灵活性。您是否需要能够轻松扩展和缩小以处理动态工作负载的GPU?如果是,请选择虚拟GPU。
•预算。根据云提供商的不同,裸机GPU服务器可能比虚拟GPU实例更昂贵。虚拟GPU通常提供更灵活的定价,这可能适用于偶尔或可变的工作负载。
您在裸机GPU和虚拟GPU之间的最终选择取决于AI/ML项目的具体要求,包括性能需求、可扩展性要求、工作负载类型和预算限制。评估这些因素可以帮助确定最合适的GPU选项。
选择Gcore获得一流的AI GPU
Gcore提供配备NVIDIA H100、A100和L40S GPU的裸机服务器。使用3.2 Tbps InfiniBand接口,您可以将H100或A100服务器组合成可扩展的GPU集群,用于训练和调整大规模机器学习模型或高性能计算(HPC)。
如果您正在寻找一种可扩展且低延迟的全局AI推理解决方案,请探索边缘的Gcore推理。它特别有利于对延迟敏感的实时应用程序,如生成式人工智能和对象识别。
猜你喜欢